

DOM(Document Object Model)
- 브라우저의 렌더링 엔진은 웹 문서를 로드한 후, 파싱을 진행
- html문서를 브라우저가 파싱해와서 생긴 모든 태그의 집합(트리 구조) 이것을 DOM이라고 한다(맞나?)
- 왜 브라우저는 DOM을 굳이 만들어내는 걸까?
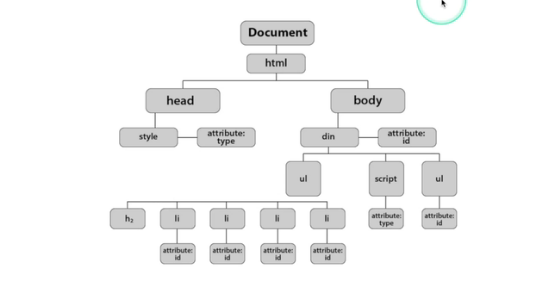
- DOM의 목적
- 각 노드를 객체로 생각하면 문서를 더욱 편리하게 관리할 수 있다.
- DOM을 다루는 예시
- DOM Tree를 순회해서 특정 원소를 추가할 수 있다.
- DOM Tree를 순회해서 특정 원소를 찾을 수 있다.
- DOM으로 바꾸면 좋은 점
- 원하는 요소를 동적으로 변경해 줄 수 있다.
- 원하는 요소를 쉽게 찾을 수 있다.
- 브라우저의 렌더링 요약
- 브라우저는 HTML을 파싱해서 DOM을 생성한다.
- 이를 바탕으로 요소를 변경하거나 찾을 수 있다.
- 파이썬으로 HTML을 분석하는 HTML Parser가 필요하다.
BeautifulSoup 설치 & 사용해보기
- beautifulsoup4 설치
!pip install beautifulsoup4
- BeautifulSoup 객체 만들기
import requests
res = requests.get("http://www.example.com")
print(res.text)from bs4 import BeautifulSoup
# BeautifulSoup 객체를 만들어본다.
# 첫번째 인자로는 reponse의 body를 텍스트로 전달한다.
# 두번째 인자로는 "html"로 분석한다는 것을 명시해준다.
soup = BeautifulSoup(res.text, "html.parser")# 객체 soup의 .prettify()를 이용하면 분석된 HTML을 보기 편하게 반환해준다.
print(soup.prettify())
- soup 객체를 통해서 우리는 HTML의 특정 요소를 가지고 올 수 있다.
# title 태그 가져오기
soup.title
# <h1> 태그로 감싸진 요소 하나 찾기
soup.find("h1")
- 특정 요소들 찾기: find_all()
# <p> 태그로 감싸진 요소들 찾기
soup.find_all('p')
- 태그 이름 가져오기
# 태그 이름 가져오기
h1 = soup.find('h1')
h1.name
- 태그 내용 가져오기
# 태그 내용 가져오기
h1.text
원하는 요소 가져오기 - 1
- 아래 싸이트에서 스크랩 실습을 진행했다.

- 스크래핑에 필요한 모듈 불러오기
# 스크래핑에 필요한 라이브러리 불러오기
import requests
from bs4 import BeautifulSoup# 예시 사이트에 요청을 보내고, 응답을 바탕으로 BeautifulSoup 객체를 생성한다.
res = requests.get("http://books.toscrape.com/catalogue/category/books/travel_2/index.html")
soup = BeautifulSoup(res.text, "html.parser")- <h3>태그에 해당하는 요소 하나 찾아보기
# <h3> 태그에 해당하는 요소를 하나 찾아보기
soup.find('h3')
- 찾아온 데이터들은 모두 객체이므로, 익숙한 방식대로 데이터를 추출할 수 있다.
- 메서드를 이용하거나
- 속성을 참조하거나
#<h3> 태그에 해당하는 모든 요소 찾아보기
h3_result = soup.find_all('h3')
len(h3_result)# book_list에서 우리가 원하는 제목만 추출해보기
for book in h3_result:
print(book.a.text)
# book_list에서 우리가 원하는 제목만 추출해보기
# for book in h3_result:
# print(book.a.text)
for book in h3_result:
print(book.a['title'])
HTML의 Locator로 원하는 요소 찾기
- Tag의 id와 class 사용하기
- id: 하나의 고유 태그를 가리키는 라벨
- class: 여러 태그를 묶는 라벨
- http://example.python-scraping.com/ 에서 실습 진행
# 아래 사이트에 요청을 보내고, 이것의 응답을 BeautifulSoup 객체로 만들어본다.
res = requests.get('http://example.python-scraping.com/')
soup = BeautifulSoup(res.text, "html.parser")- id 이용해서 요소 가져오기
# id가 result인 div 태그 찾아보기
soup.find("div", id='results')- class를 이용해서 요소 가져오기
# class가 "page-header"인 "div" 태그 찾기
soup.find("div", "page-header")원하는 요소 가져오기 - 2
- HashCode 질문 가져오기 - https://qna.programmers.co.kr/
QnA | 프로그래머스 커뮤니티
프로그래머스 QnA는 프로그래밍 문제해결을 위한 QnA서비스입니다. 프로그래밍과 관련해서 개발자들끼리 궁금한건 물어보고 아는건 함께 나눠요. C, Java, Python, Ruby등의 코드를 웹에서 직접 실행
qna.programmers.co.kr
- ❌ 과도한 요청 보내지 않기
- ❌ 받아온 정보 활용에 유의하기
- User-Agent 설정( header에 유저 정보 추가)
user_agent = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"}
res = requests.get("https://qna.programmers.co.kr/", user_agent)soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all('li', 'question-list-item')
for q in questions:
print(q.find("div", "question").find("div", "top").h4.text)
- 페이지네이션 상황에서 스크래핑 해보기
- 과도한 요청 방지를 위해 1초마다 요청을 보내기
import time
for i in range(1, 3):
res = requests.get("https://hashcode.co.kr/?page={}".format(i), user_agent)
soup = BeautifulSoup(res.text, "html.parser")
questions = soup.find_all('li', 'question-list-item')
for q in questions:
print(q.find("div", "question").find("div", "top").h4.text)
time.sleep(0.5) # 매 반복마다 0.5초의 인터벌 주기
'프로그래머스 AI 데브코스 5기 > CS' 카테고리의 다른 글
| Web Scraping 기초 - 3 (0) | 2023.03.23 |
|---|---|
| web scrapping 기초 2 (0) | 2023.03.22 |
| 양방향 연결 리스트(Doubly Linked List) (0) | 2023.03.20 |
| 연결 리스트(Linked Lists) (0) | 2023.03.20 |
| 알고리즘의 복잡도 (0) | 2023.03.20 |