

⭐ 수업에 사용된 데이터셋 : https://www.kaggle.com/datasets/imdevskp/corona-virus-report?resource=download
COVID-19 Dataset
Number of Confirmed, Death and Recovered cases every day across the globe
www.kaggle.com
1. Pandas 시작하기
- prerequisite: table
- 행과 열을 이용해서 데이터를 저장하고 관리하는 자료구조(컨테이너)
- 주로 행은 개체, 열은 속성을 나타냄
- 판다스 설치하기
pip install pandas- 판다스 임포트
import pandas as pd
2. Pandas로 1차원 데이터 다루기 - Series
- 1-D labled array
- 인덱스를 지정해줄 수 있음
s = pd.Series([1, 4, 9, 16, 26])
s
t = pd.Series({'one': 1, 'two': 2, 'three': 3, 'four':4, 'five':5})
t
- Series와 Numpy
- series는 ndarray와 유사하다.
print(s[1])
print(t[1])
t[1:3]
s[s > s.median()] # 자기 자신의 median(중앙값)보다 큰값만 조회
s[[3, 1, 4]] # 해당 인덱스 순서대로 row를 가져옴
- 넘파이의 함수를 판다스에 적용할 수도 있다.
import numpy as np
np.exp(s)
s.dtype # 데이터 타입 확인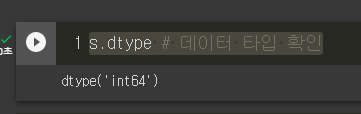
- series는 dict와 유사하다
print(t['one'])
t['six'] = 6 # 새로운 값 할당
print(t)
print('six' in t)
print('seven' in t)
t.get('seven', 0)
- series에 이름 붙이기
- 'name' 속성을 가지고 있다.
- 처음 Series를 만들 때 이름을 붙일 수 있다.
s = pd.Series(np.random.randn(5), name="random_nums")
s
s.name = "임의의 난수"
s
3. Pandas로 2차원 데이터 다루기 - dataframe
- dataframe?
- 2-D labeled table
- 인덱스를 지정할 수도 있음
d = {"height": [1, 2, 3, 4], "weight": [30, 40, 50, 60]}
df = pd.DataFrame(d)
df
## dtype 확인
df.dtypes
- from csv to dataframe
- comma seperated value를 Dataframe으로 생성해줄 수 있다.
import os
path = '/content/drive/MyDrive/data/covid/'
covid = pd.read_csv(os.path.join(path, 'country_wise_latest.csv'))
covid.head()
- pandas 활용 1 - 일부분만 관찰하기
# 위에서부터 5개를 관찰하는 방법(함수)
covid.head(5)
# 아래에서부터 5개를 관찰하는 방법(함수)
covid.tail(5)
- pandas 활용2 - 데이터 접근
- df['column_name'] or df.column_name
covid['Confirmed'][:5]
covid.Confirmed[:5]
- dataframe의 각 column은 series다
- pandas 활용 3 - '조건'을 이용해서 데이터 접근하기
# 신규 확진자가 100명이 넘는 나라 찾아보기
covid[covid['New cases'] > 100]
- WHO 지역이 동남아시아인 나라 찾기
covid['WHO Region'].unique()
covid[covid['WHO Region'] == 'South-East Asia']
- pandas 활용4 - 행을 기준으로 데이터 접근하기
# 예시 데이터
books_dict = {
"Available": [True, True, False],
"Location": [102,215,323],
"Genre": ['Programming', 'Physics', 'Math']
}
books_df = pd.DataFrame(books_dict, index=['버그란 무엇인가', '두근두근 물리학', '미분해줘 홈즈'])
books_df
- 인덱스를 이용해서 가져오기: .loc[row, col]
books_df.loc['버그란 무엇인가']
# 미분해줘 홈즈 책이 대출 가능한지
books_df.loc['미분해줘 홈즈', 'Available']
- 숫자 인덱스를 이용해서 가져오기: .iloc[rowidx, colidx]
books_df.iloc[0,1]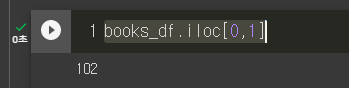
- 판다스 활용5 - groupby
- split: 특정한 기준을 바탕으로 DataFrame을 분할
- apply: 통계함수 - sum(), mean(), median(), - 을 적용해서 각 데이터를 압충
- combine: Apply된 결과를 바탕으로 새로운 Series를 생성(group_key : applied_value)
# WHO Region 별 확진자 수
# 1.covid에서 확진자 수 column만 추출한다.
# 2. 이를 covid의 WHO Region을 기준으로 groupby한다.
covid_by_region = covid['Confirmed'].groupby(by=covid['WHO Region'])
covid_by_region
covid_by_region.sum()
# 국가당 감염자 수
covid_by_region.mean()
mission
1. covid 데이터 100 case 대비 사망률(Deaths / 100 cases)이 가장 높은 국가는?
covid.sort_values('Deaths / 100 Cases', ascending=False)['Country/Region'][0]
2.covid 데이터에서 신규 확진자가 없는 나라 중 WHO Region이 'Europe'를 모두 출력하면?
no_new_covid = covid[covid["New cases"]==0]
result = no_new_covid[no_new_covid['WHO Region'] == 'Europe']
result
3. 아보카도 데이터를 이용해 각 Region 별로 아보카도가 가장 비싼 평균가격(AveragePrice)을 출력하면?
path_2 = '/content/drive/MyDrive/data/avocado/'
avocado = pd.read_csv(os.path.join(path_2, 'avocado.csv'), index_col=0)
result = avocado['AveragePrice'].groupby(by=avocado['region']).max()
result
'프로그래머스 AI 데브코스 5기 > Data study' 카테고리의 다른 글
| Matplotlib의 여러 plot들 (0) | 2023.03.30 |
|---|---|
| Matplotlib으로 데이터 시각화 하기 (0) | 2023.03.30 |
| Linear Algebra with Numpy (0) | 2023.03.27 |
| Numpy 연산 (2) | 2023.03.27 |
| 시각화 결과로 요약하기 - seaborn (0) | 2023.03.23 |