

EDA?
- 데이터를 분석하는 기술적 접근은 굉장히 많다.
- 데이터 그 자체만으로부터 인사이트를 얻어 내는 접근법!(시각화나 통계적 기법을 사용하기도 한다.)
EDA의 process
- 분석의 목적과 변수 확인
- 데이터 전체적으로 살펴보기(상관관계, NA값 등)
- 데이터의 개별 속성 파악하기
EDA with Example - Titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
1. 분석의 목적과 변수 확인
- 살아 남은 사람들은 어떤 특징을 갖고 있을까?
- 라이브러리 준비
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inlineimport os
path = '/kaggle/input/titanic/'
titanic_df = pd.read_csv(os.path.join(path, 'train.csv'))- 분석의 목적과 변수 확인
- 타이타닉 호에서 생존한 생존자들은 어떤 사람들일까?
import os
path = '/kaggle/input/titanic/'
titanic_df = pd.read_csv(os.path.join(path, 'train.csv'))
- Cabin 칼럼의 경우 첫번째 데이터 값이 Nan이다 이는 여러가지 의미를 시사한다.
- 특정한 값으로 메꿔줘야 할지
- 버릴지 등등
- 각 칼럼의 데이터 타입 확인하기
titanic_df.dtypes
2. 데이터 전체적으로 살펴보기
- 데이터 전체 정보를 얻는 함수: .describe() - 수치 데이터에 대한 정보를 제공!
titanic_df.describe()
- 상관계수 확인 - corr()
titanic_df.corr()
- Correlation is not Causation
- 상관성: A가 증가하더니 B도 증가하더라 처럼 이런 경향성을 나타내는 수치이다.
- 인과성: A -> B A로부터 B가 발생했다는 종속 관계를 의미한다.
- 결측치 확인
titanic_df.isnull().sum()
3. 데이터 개별 속성 파악하기
Survived
titanic_df['Survived'].value_counts()
- 생존자수와 사망자수 barplot으로 그려보기
sns.countplot(x='Survived', data=titanic_df)
plt.show()
PCLASS
- Pclass에 따른 인원 파악
titanic_df[titanic_df['Survived'] == 1]['Pclass'].value_counts() # 값의 차이가 나는 이유는?
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).count()
- 생존자 인원?
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).sum()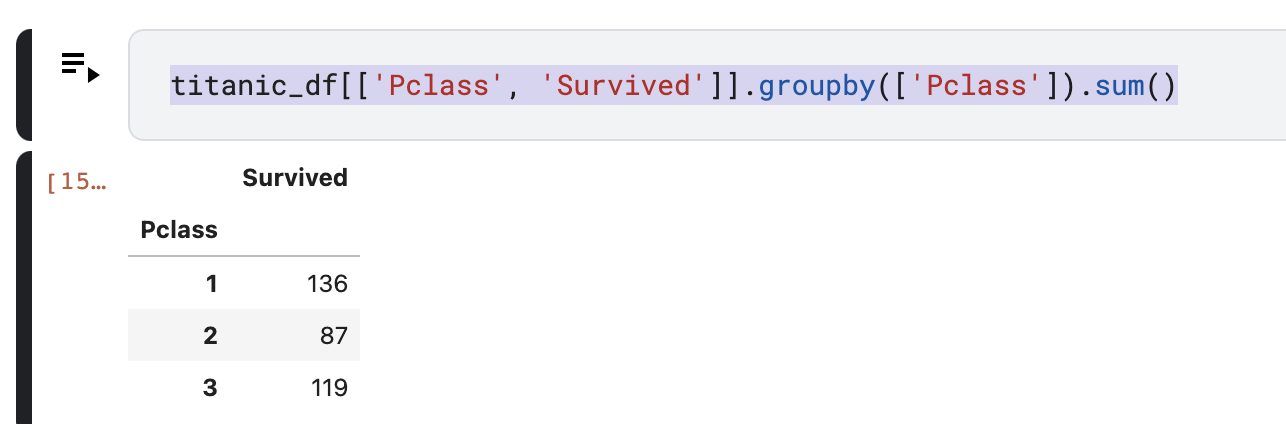
- 생존 비율?
titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).mean()
- 히트맵 활용
sns.heatmap(titanic_df[['Pclass', 'Survived']].groupby(['Pclass']).mean())
plt.show()
Sex
titanic_df.groupby(['Survived', 'Sex']).count()
- catplot
sns.catplot(x='Sex', col='Survived', kind='count', data=titanic_df)
plt.show()
Age
- remind: 결측치가 존재 했엇다!
- 경향성을 한번 먼저 분석하고 어떻게 다룰지 결정하도록 해보자
titanic_df.describe()['Age']
- 연속성 데이터의 경향성을 파악한다? -> 커널밀도그림
fig, ax = plt.subplots(1, 1, figsize=(10, 5))
sns.kdeplot(x=titanic_df[titanic_df['Survived'] == 1]['Age'], ax=ax)
sns.kdeplot(x=titanic_df[titanic_df['Survived'] == 0]['Age'], ax=ax)
plt.legend(['Survived', 'Dead'])
plt.show()
Appendix 1: Sex + Pcalss vs Survived
sns.catplot(x='Pclass', y='Survived', data=titanic_df, kind='point')
plt.show()
- 막대기는 신뢰구간을 의미한다.
sns.catplot(x='Pclass', y='Survived', hue='Sex', data=titanic_df, kind='point')
plt.show()
- 단일 변수일땐 보이지 않던 관계가 보인다!
Appendix 2: Age + Pclass
titanic_df['Age'][titanic_df.Pclass==1].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass==2].plot(kind='kde')
titanic_df['Age'][titanic_df.Pclass==3].plot(kind='kde')
plt.legend(['1st class', '2nd class','3rd class'])
plt.show()
Mission: It's yout turn
1. 본문에서 언급된 feature를 제외하고 유의미한 feature를 1개 이상 찾아보자.
- hint? Fare? Sibsp Parch
2. Kaggle에서 Dataset을 찾고, 이 Dataset에서 유의미한 Feature를 3개 이상 찾고 이를 시각화해보자
함께 보면 좋은 도큐먼트: numpy, pandas, seaborn, matplotlib
무대뽀로 하기 힘들다면 다음 hint와 함께 시도해보자
1. 데이터를 톺아보자
- 각 데이터는 어떤 자료형을 갖고있는지
- 데이터에 결측치는 없고 있다면 이를 어떻게 메꿔줄것인지
- 데이터의 자료형을 바꿔줄 필요가 있는지 -> 범주형의 one-hot- encoding
2. 데이터에 대한 가설을 세워보자
- 가설은 개인의 경험에 의해서 도출되어도 상관없다.
- 가설은 명확할수록 좋다. ex) titanic에서 survived는 성별과 상관관계가 있다.
3. 가설을 검증하기 위한 증거를 찾아보자
- 이 증거는 한눈에 보이지 않을수도 있다. 이때 수업시간에 배운 테크닉을 활용해보자
- groupby()를 통해 그룹화된 정보의 통계량을 도입하면 어떨까?
- .merge()를 통해 두개의 데이터프레임을 합쳐보는건 어떨까?
- 시각화를 일목요연하게 보여주면 어떨까?
'프로그래머스 AI 데브코스 5기 > Data study' 카테고리의 다른 글
| Seaborn (0) | 2023.03.30 |
|---|---|
| Matplotlib의 여러 plot들 (0) | 2023.03.30 |
| Matplotlib으로 데이터 시각화 하기 (0) | 2023.03.30 |
| Pandas 시작하기 (0) | 2023.03.29 |
| Linear Algebra with Numpy (0) | 2023.03.27 |